|
|
四、正则解析模块re
re模块使用流程
方法一
r_list=re.findall('正则表达式',html,re.S)方法二
# 创建正则编译对象
pattern = re.compile('正则表达式',re.S)
r_list = pattern.findall(html)
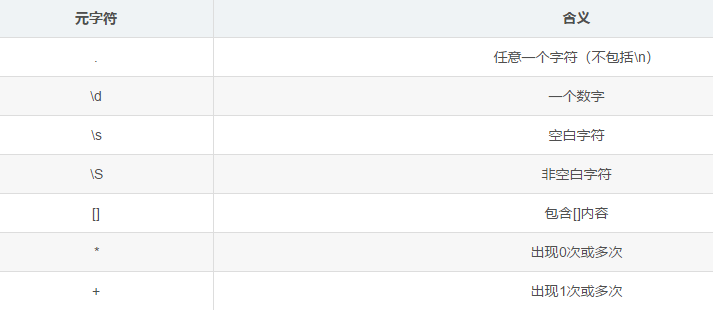
正则表达式元字符
推荐使用方法一
# 匹配任意一个字符的正则表达式
import re
# 方法一
pattern = re.compile('.',re.S)
# 方法二
pattern = re.compile('[\s\S]')
贪婪匹配和非贪婪匹配
贪婪匹配(默认)
1、在整个表达式匹配成功的前提下,尽可能多的匹配 * + ?
2、表示方式: .* .+ .?
非贪婪匹配
1、在整个表达式匹配成功的前提下,尽可能少的匹配 * + ?
2、表示方式: .*? .+? .??
正则表达式分组
作用
在完整的模式中定义子模式,将每个圆括号中子模式匹配出来的结果提取出来
示例
import re
s = 'A B C D'
p1 = re.compile('\w+\s+\w+')
print(p1.findall(s))
# ['A B','C D']
p2 = re.compile('(\w+)\s+\w+')
print(p2.findall(s))
# ['A','C']
p3 = re.compile('(\w+)\s+(\w+)')
print(p3.findall(s))
# ['A B','C D']
# [('A','B'),('C','D')]
分组总结
1、在网页中,想要什么内容,就加()
2、先按整体正则匹配,然后再提取分组()中的内容
如果有2个及以上分组(),则结果中以元组形式显示 [(),(),()]
字符串常用方法
# 'hello world'.strip() --> 'hello world'
# 'hello world'.split(' ') --> ['hello','world']
# 'hello world'.replace(' ','#') -> 'hello#world'
五、requests模块
安装
Windows
# 方法一
进入cmd命令行 :python -m pip install requests
# 方法二
右键管理员进入cmd命令行 :pip install requests
常用方法
requests.get()
作用
# 向网站发起请求,并获取响应对象
res = requests.get(url,headers=headers)
参数
1、url :需要抓取的URL地址
2、headers : 请求头
3、timeout : 超时时间,超过时间会抛出异常
响应对象(res)属性
1、encoding :响应字符编码
res.encoding = 'utf-8'
2、text :字符串
3、content :字节流
4、status_code :HTTP响应码
5、url :实际数据的URL地址
# 方式一
res = requests.get(url,headers=headers)
res.encoding = 'utf-8'
html = res.text
# 方式二
res = requests.get(url,headers=headers)
html = res.content.decode('utf-8')
非结构化数据保存
with open('xxx.jpg','wb') as f:
f.write(res.content)
查询参数-params
参数类型
字典,字典中键值对作为查询参数
使用方法
1、res = requests.get(url,params=params,headers=headers)
2、特点:
* url为基准的url地址,不包含查询参数
* 该方法会自动对params字典编码,然后和url拼接
示例
import requests
baseurl = '百度贴吧--全球最大的中文社区
params = {
'kw' : '赵丽颖吧',
'pn' : '50'
}
headers = {'User-Agent' : 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)'}
# 自动对params进行编码,然后自动和url进行拼接,去发请求
res = requests.get(baseurl,params=params,headers=headers)
res.encoding = 'utf-8'
print(res.text)
requests模块参数总结
1、url
2、params : {}
3、proxies: {}
4、auth: ()
5、verify: True/False
6、timeout
requests.post()
适用场景
Post类型请求的网站
参数-data
response = requests.post(url,data=data,headers=headers)
# data :post数据(Form表单数据-字典格式)
请求方式的特点
# 一般
GET请求 : 参数在URL地址中有显示
POST请求: Form表单提交数据
六、xpath解析
定义
XPath即为XML路径语言,它是一种用来确定XML文档中某部分位置的语言,同样适用于HTML文档的检索
示例HTML代码
<ul class=&#34;book_list&#34;>
<li>
<title class=&#34;book_001&#34;>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>69.99</price>
</li>
<li>
<title class=&#34;book_002&#34;>Spider</title>
<author>Forever</author>
<year>2019</year>
<price>49.99</price>
</li>
</ul>
匹配演示
1、查找所有的li节点
//li
2、查找li节点下的title子节点中,class属性值为&#39;book_001&#39;的节点
//li/title[@class=&#34;book_001&#34;]
3、查找li节点下所有title节点的,class属性的值
//li//title/@class
# 只要涉及到条件,加 []
# 只要获取属性值,加 @
选取节点
1、// :从所有节点中查找(包括子节点和后代节点)
2、@ :获取属性值
# 使用场景1(属性值作为条件)
//div[@class=&#34;movie&#34;]
# 使用场景2(直接获取属性值)
//div/a/@src
匹配多路径(或)
xpath表达式1 | xpath表达式2 | xpath表达式3
常用函数
1、contains() :匹配属性值中包含某些字符串节点
# 查找class属性值中包含&#34;book_&#34;的title节点
//title[contains(@class,&#34;book_&#34;)]
# 匹配所有段子的 div 节点
//div[contains(@id,&#34;qiushi_tag_&#34;)]
<div class=&#34;article block untagged mb15 typs_long&#34; id=&#34;qiushi_tag_122044339&#34;>
</div>
<div class=&#34;article block untagged mb15 typs_long&#34; id=&#34;qiushi_tag_122044339&#34;>
</div>2、text() :获取节点的文本内容
# 查找所有书籍的名称
//ul[@class=&#34;book_list&#34;]/li/title
#结果:<element title at xxxx>
//ul[@class=&#34;book_list&#34;]/li/title/text()
#结果:&#39;Harry Potter&#39;
1、获取猫眼电影中电影信息的 dd 节点
//dl[@class=&#34;board-wrapper&#34;]/dd
2、获取电影名称的xpath://dl[@class=&#34;board-wrapper&#34;]/dd//p[@class=&#34;name&#34;]/a/text()
获取电影主演的xpath://dl[@class=&#34;board-wrapper&#34;]/dd//p[@class=&#34;star&#34;]/text()
获取上映商检的xpath://dl[@class=&#34;board-wrapper&#34;]/dd//p[@class=&#34;releasetime&#34;]/text()
匹配规则
1、节点对象列表
# xpath示例: //div、//div[@class=&#34;student&#34;]、//div/a[@title=&#34;stu&#34;]/span
2、字符串列表
# xpath表达式中末尾为: @src、@href、text()
xpath高级
1、基准xpath表达式: 得到节点对象列表
2、for r in [节点对象列表]:
username = r.xpath(&#39;./xxxxxx&#39;)
# 此处注意遍历后继续xpath一定要以: . 开头,代表当前节点
lxml解析库
使用流程
1、导模块
from lxml import etree
2、创建解析对象
parse_html = etree.HTML(html)
3、解析对象调用xpath
r_list = parse_html.xpath(&#39;xpath表达式&#39;)
# 只要调用xpath,结果一定为列表
练习
from lxml import etree
html = &#39;&#39;&#39;<div class=&#34;wrapper&#34;>
<i class=&#34;iconfont icon-back&#34; id=&#34;back&#34;></i>
<a href=&#34;/&#34; id=&#34;channel&#34;>新浪社会</a>
<ul id=&#34;nav&#34;>
<li><a href=&#34;http://domestic.firefox.sina.com/&#34; title=&#34;国内&#34;>国内</a></li>
<li><a href=&#34;http://world.firefox.sina.com/&#34; title=&#34;国际&#34;>国际</a></li>
<li><a href=&#34;http://mil.firefox.sina.com/&#34; title=&#34;军事&#34;>军事</a></li>
<li><a href=&#34;http://photo.firefox.sina.com/&#34; title=&#34;图片&#34;>图片</a></li>
<li><a href=&#34;http://society.firefox.sina.com/&#34; title=&#34;社会&#34;>社会</a></li>
<li><a href=&#34;http://ent.firefox.sina.com/&#34; title=&#34;娱乐&#34;>娱乐</a></li>
<li><a href=&#34;http://tech.firefox.sina.com/&#34; title=&#34;科技&#34;>科技</a></li>
<li><a href=&#34;http://sports.firefox.sina.com/&#34; title=&#34;体育&#34;>体育</a></li>
<li><a href=&#34;http://finance.firefox.sina.com/&#34; title=&#34;财经&#34;>财经</a></li>
<li><a href=&#34;http://auto.firefox.sina.com/&#34; title=&#34;汽车&#34;>汽车</a></li>
</ul>
<i class=&#34;iconfont icon-liebiao&#34; id=&#34;menu&#34;></i>
</div>&#39;&#39;&#39;
# 获取所有 a 节点的文本内容
//ul//li/a/text()
# 获取所有 a 节点的 href 的属性值
//ul//li/a/@href
# 获取 图片、军事、...,不包括新浪社会
//ul//li/a/title[not(contains(@title,&#34;社会&#34;))]/text()
- 未完-
请移步专栏同名公众号查看。 |
|



 发表于 2022-12-17 19:19:26
发表于 2022-12-17 19:19:26